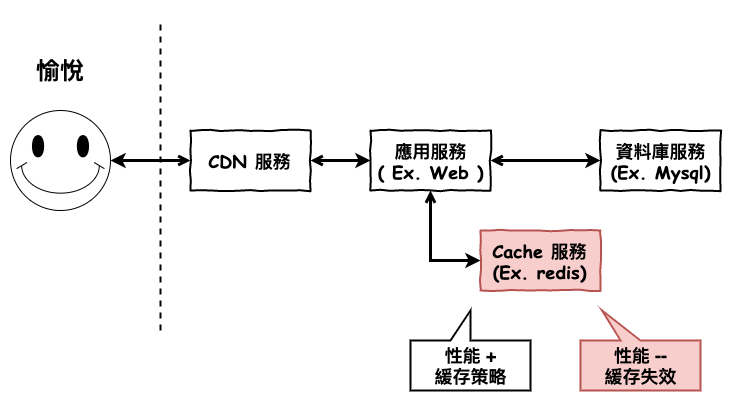
上一篇文章中咱們已經學習了一些緩存基本的策略,那接下來我們要來理解一下一個重要的主題 :
如果緩存失效的情況,與可能會發生什麼事情呢 ?
基本上緩存失效後的結果,會很慘,尤其是你當初建立緩存時,就是已經為了讀取接近性能臨異值而建立的情況,當緩存一失效,你的資料庫也會瞬間爆掉,然後用戶就不愈悅,你就完了。
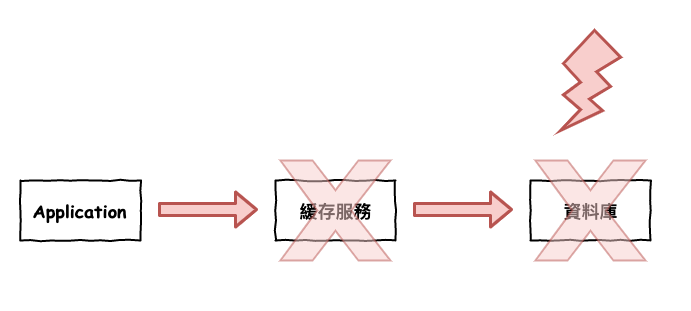
圖 1 : 緩存失效圖
而在實務上,緩存失效大至可以分為以下幾類,也就是咱們接下來每個章節 :
這個的主要情境如下 :
查詢一個不存在的資料,由於沒命中緩存,因此會一直往 DB 穿,如下圖 2 所示。
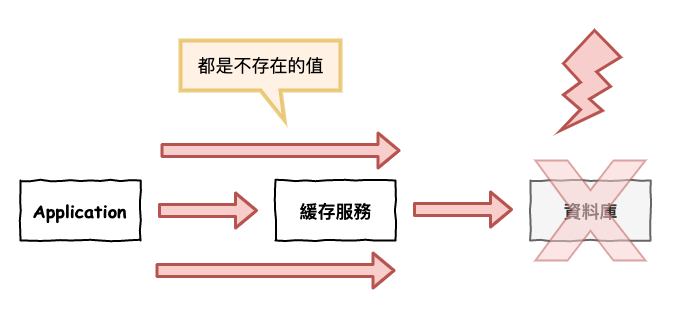
圖 2 : 緩存穿透
通常這種情況有可能是前端出了錯,導致一直送不存在的資料,又或是人為刻意,就是要有人想打爆你整個系統。
這種方法就是,當用戶使用 a key 去 redis 找發現沒有 cache,然後再去 db 抓,也發現沒有,然後就將『 這個 a key 是空值 』也寫入到緩存中 ( 可以給它設個到期時間 ),如下程式碼範例。
這樣後面有人在使用這個 key 去打,會在 cache 這被防下來,然後將算後來真的有寫入 a key 時,咱們緩存寫入流程也是會將它處理 ( 詳見前篇文章 )。
// 概念碼
const userId = 'A';
if(isExistInCache(userId)){
return getCache(userId);
}
const user = getUser(userId);
let cacheValue = user;
if( user === null ){
cacheValue = getDefaultEmptyValue();
}
setCache(userId, cacheValue);
不過這種方案還是有缺點
它無法防護隨機編號的攻擊,因為每一次都是不同的
它的基本解法概念為 :
建立一個很大的 hash 來『 存放值 』,當如果是『 不存在的值 』則會再檢查時被過濾掉。
問個問題 ~ 這裡用 hash 感覺就可以處理了,為啥要用啥布隆過濾器概念不是很像嗎 ?
咱們寫來說說 hash 的處理方案。
首先 hash 就是一個 key 與 value 的對應,然後 key 會通過 hash 函數來進行轉換,如下圖 3 所示。
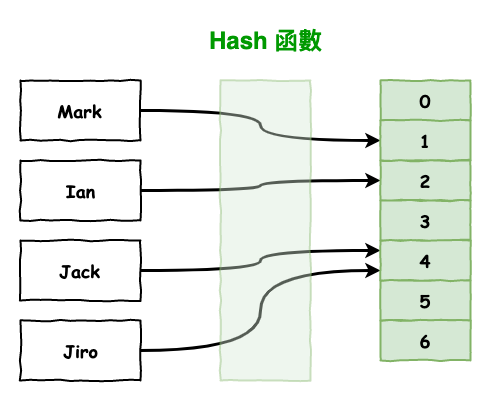
圖 3 : hash
這裡順到說一下,上圖 3 的 jack 與 jiro 這兩個 key 通過 hash 有可能會指到相同的 value 4,那這樣如何處理呢 ?
比較常見有兩種方案 :
在補充一下 hash 的新增與抓取操作時間複雜都是 o(1),然後 linklist 新增是 o(1),但是抓取就是 o(n),而如果變成太長的 linklist,你要抓值時,就代表要一個一個看看,也就是 o(n) 的操作。
那 hash 又與布隆過濾器有啥差別 ?
兩則概念很相似,但問題出在 :
如果 key 非常多的情況下
hash 有可能會爆,因為你可以想成它是每一個 key,就會花個空間來儲,而布隆過濾器就是可以解決這一點。
簡單來說它可以花少少的空間來判斷,一個 key 是否存在,但然後它的缺點就在於 :
有誤判率
所以這個演算法不適合用在 100% 確定的場景,而是只能用在大約有 70 ~ 80 % 左右的準確度就夠了,例如緩存穿透、垃圾郵件過濾、爬蟲 url 去除重複。
詳細的布隆過濾器原理,這裡就不說了,有興趣的友人請自行查查。
好然後拉回來,如果要用布隆過濾器來處理緩存穿透時,咱們大概會用以下程式碼來實現 :
const target = 'Mark';
// 這裡會先判斷 target 有沒有存在,透布隆過濾器表來判斷
if(!isExistBoolFilter(target)){
return;
}
if(isExistInCache(target)){
rturn cache[target];
}
return db.get(target);
然後我覺得比較重要的點在於,你的 boolFilter 要如何維護呢 ?
目前想到比較簡單的處理是,當 target 被新增的時後,則更新一次記憶體中的 boolFilter,而如果是移除了,則不理它,反正 cache 那會防。
別忘了這裡是為了達到 :
儘可能的過濾資料,別讓緩存服務爆了。
所以你要確保,即使 boolFilter 誤判了,那業務運行還是不會出錯。
對了,那這個 boolFilter 要存那呢 ?
比較建議是存在緩存服務外的另一個 redis 上。
在單機時存記憶體上還沒啥毛病,就算機器重開了,那也項多是去 db 重拉一份資料然後再存入記憶體,但多機時你還要考慮每台機器 boolFilter 更新的問題。
這個的主要情境如下 :
當緩存在同一個時間內大量失效時(因為到期或啥的)。
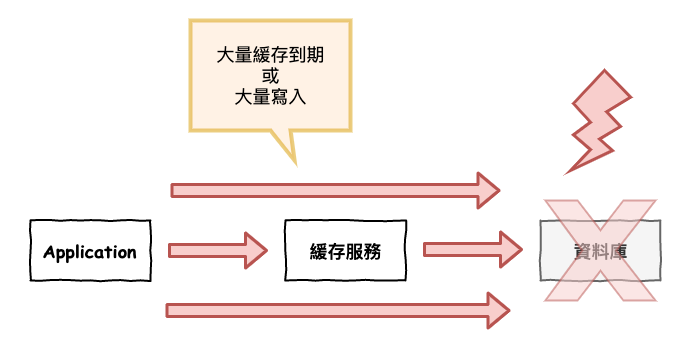
圖 4 : 緩存雪崩
這種情況基本上分為以下兩個情境 :
首先說說第一個,上一章節有提到,通常會建議,在寫入緩存時,會給它設置一個到期時間,免得上面殘留太多的那些忘記寫清除程式,或因系統故障導致沒有清除的不需要的緩存。下面為 redis 設定 key 的到期時間小範例。
redis> SET mykey "Hello"
"OK"
redis> EXPIRE mykey 10
(integer) 1
而這時如果有大量的 key,它們到期時間設置相同,那失效的那個瞬間就會產生所謂的緩存雪崩。
這種方案的解法通常為,給它設置一個隨機變數 :
EXPIRE mykey 10 + random
而至於第二種情況,瞬間的大量寫入,上一章節咱們要有說在緩存最少是使用『 淘汰 』,而不是用『 更新 』,但是如果這時有瞬間的大量寫入,那就是產生大量的『 淘汰 』,那這時也會產生所謂的緩存雪崩。
這一題目前想了一下,事實上發生機率很低,因為會建立緩存的資料前提假設之一就是更新頻率低,而在這個情況下還是會發生這種情況的另一種可能就在於『 有人在批次大量修改資料 』。
如果是在這種批次的情況下,那就建議直接用『 批次更新 』緩存,而不要在正規使用『 淘汰 』,先說一下系統內的運行一樣是『 淘汰 』,只是當發現有需要大量修改資料時,請手動的『 更新 』緩存。
如果都不是上面說的這種情況,而還是發生了,那就可能需要使用『 隊列服務 』來讓這些寫操作排隊,不要一口氣灌到緩存服務,但當然,這會對架構與性能可能都會有不少影響,所不定也會出現一堆坑。
就是緩存服務炸掉了,導致直接灌到資料庫層去,如下圖 5 所示。
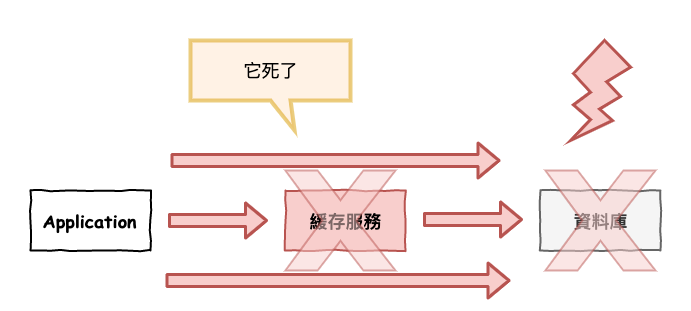
圖 5 : 緩存服務炸了
~ 小備註 ~
這裡應該會有人覺得很奇怪,假設咱們程式碼如下所示,那基本緩存服務掛了,資料庫那層應該是不會處理啊,因為錯誤囉。
const target = 'Mark';
if(isExistInCache(target)){
rturn cache[target];
}
return db.get(target);
對是沒錯。
但這時你要想想,這樣是對的嗎 ?
緩存是為了什麼 ? 是為了加快查詢的速度與保護資料庫層。那你想想,你覺得緩存服務掛了,要讓整個『 系統業務 』都死嗎,如果你有個記錄 log 的服務掛了,也要整個系統都死嗎 ?
不不 ~ 這樣不太對 ~ 別忘了我們追求的是『 好的系統 』,是要讓客戶愉悅的,如果一個業務系統要綁十個服務,然後每個服務都要完成,業務才算完成,那你想想你的業務完成機率是多少呢 ? 順到說一下,如果一個服務裡需要綁那麼多服務,請考慮開拆。
緩存掛了對用戶來說,有時也感覺不到,log 服務掛了對用戶來說更感覺不到,所以通常咱們會在這 isExistInCache 這方法裡面加個 try cache 然後繼續去 db 查詢。
這樣才能保證緩存服務就算故障了,也不影響『 系統業務 』。
這個架構基本算是最基本的 redis 高可用架構,它主要的目的在於 :
當 master 掛了,一台 slave 馬上來補 ( 就是升為 master )
所以當緩存服務有建立這架構後,就可以解決緩存服務炸了導致大量請求直接灌入到 db 的問題,因為有後補者。
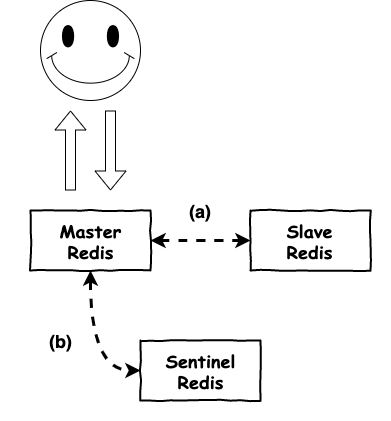
圖 6 : master-slave 架構
這裡簡單說明一下這個架構,這個架構基本上是有三個服務 :
圖 6 中,這裡有兩個小重點,首先第一個 master slave 會一直運行資料同步 ( a 的部份 ),這樣才能保證 slave 轉換到 master 時,有相同的資料,而第二點為 sentinel 它會不斷的監控這 master ( b 的部份 ),當它發現 master 掛了,就會將某個 slave 上架上來。
小備註
傳統它這個架構,它會有三個 sentinel, 主要的原因有兩個 :
其中 sentinel 仲裁會比較特別一點,這個東西就是用來決定 master 要不要下掉的機制。一台 master 要下掉需要由多個 sentinel 來投票,如果 n 個 sentinel 同意 master 掛掉,則進行 failover ( 就是 slave 補上 )。
本篇文章中,咱們介紹了幾種緩存失效的類型 :
基本上緩存穿透我目前還比較少碰到,雖然當初再開發時有想到這問題,但後來想想發生機率不高,就有點懶的解…… ( 這不算好事情,請別學 )。然後我也是在查資料時才知道有布隆過濾器這個解法。
而至於緩存雪崩這問題,這就還真的碰到不少次,最後也是給每個 key 的到期時間,給它加個大秒 10 秒以內的隨機亂數,才比較安全一點。但如果真的沒辦法給你就要考慮 key 的退場方案新機制,例如用 queue 來處理之類的。
最後緩存服務炸了這件事情麻,還真沒啥發生過,因為咱家 redis 基本型就是 master-slave 炸了可以馬上的換過來。
但是最近咱們在談討一個問題 :
如果 redis 有被應用層 connection pool 連線住,那 failover 機制可以正常運行嗎 ?
目前我們發現好像不會正常運行,會卡住,但根本原因還要再研究一下,之後有空在發篇文來談談。

